
胸小的姑娘一般脾气都特大,胸大的姑娘一般脾气都特好,因为古语有云:穷凶极恶有容乃大!
前言
对于系统中的一组数据而言,必不可少地对应有唯一标识。简单的单体应用可以使用数据库的自增 ID 作为唯一标识。而在复杂的分布式系统中,就需要一些特定的策略去生成对应的分布式 ID。
常见的项目中 ID 会有以下两个特点:
- 全局唯一性。
- 趋势递增(对于使用 MySQL 的项目而言)。
因为一般 ID 会作为数据库的主键存储,而在 MySQL InnoDB 中使用的是聚簇索引,使用有序的 ID 可以保证写入性能。
一般在分布式系统中,会有一个单独的服务来生成 ID。而这个服务则需要保证高可用性、高QPS 与安全性。另外生成的 ID 是不应该对外暴露的,如果非要对外展示,最好是无规则、不规律的编码。
生成策略
UUID
UUID (Universally Unique Identifier) 生成的是一个长度为 32 的 16 进制格式的字符串。UUID 有多个版本,各版本算法不同。但核心思想是一致的,基本上都是结合机器的网卡、当前时间、一个随机数来生成特定长度的字符串。
优点:性能好、高可扩展性:本地生成,无网络消耗,不需要考虑性能瓶颈。
缺点:
- 无法保证趋势递增。
- UUID 过长,如果需要在数据库存储,作为主键建立索引效率低。
适用场景:不需要考虑空间占用,不需要生成有递增趋势,且不在 MySQL 中存储。
Snowflake
snowflake 是 Twitter 开源的一个 ID 生成算法。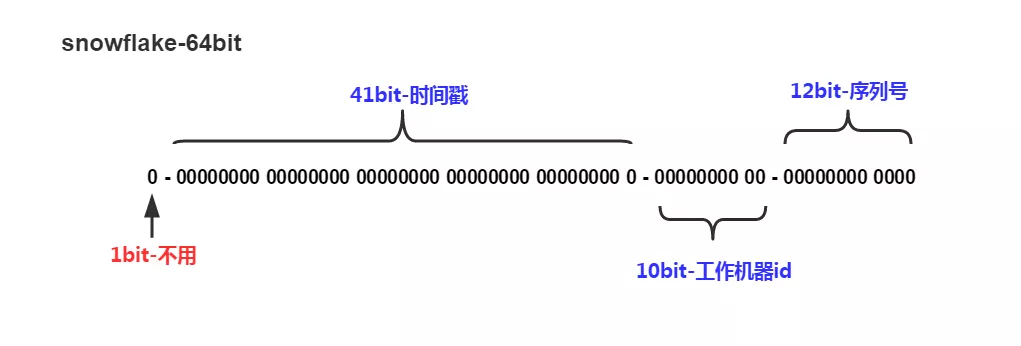
- 首位符号位:因为 ID 一般为正数,该值为 0。
- 41 位时间戳(毫秒级):
时间戳不是当前时间的时间戳,而是存储时间戳的差值(当前时间戳 - 起始时间戳(起始时间戳需要程序指定))理论上可以最多使用
(1 << 41) / (1000x60x60x24x365) = 69年。10 位数据机器位:包括 5 位数据标识位和 5 位机器标识位,也就是说最多可以部署节点数为:
1 << 10 = 1024。- 12 位毫秒内的序列:同一节点、同一时刻最多生成 ID 数
1 << 12 = 4096。
最后生成结果为 64 位 Long 型数值。
优点
- 趋势递增,且按照时间有序。
- 性能高、稳定性高、不依赖数据库等第三方系统。
- 可以按照自身业务特性灵活分配 bit 位。
缺点
- 依赖于机器时钟,时钟回拨会造成暂不可用或重复发号。
在分布式系统中,每台机器上的时钟不可能完全同步。在同步各个服务器的时间时,有一定几率发生时钟回拨。
适用场景:要求高性能,可以不连续,数据类型为 long 型。
Flicker
Flicker 方案主要思路是设计单独的库表,利用数据库的自增 ID 来生成全局 ID。
1 | CREATE TABLE ticket_center ( |
stub: 票根,对应需要生成 Id 的业务方编码,可以是项目名、表名甚至是服务器 IP 地址。
MyISAM:默认表类型,基于传统的 ISAM 类型。ISAM是 Indexed Sequential Access Method (有索引的顺序访问方法) 的缩写,它是存储记录和文件的标准方法。不是事务安全的,而且不支持外键。如果执行大量的 select,MySql 存储引擎选用 MyISAM 比较适合。
可以使用下面的SQL 获取 ID:
1 | REPLACE INTO ticket_center (stub) VALUES ('test'); |
Replace into先尝试插入数据到表中,如果发现表中已经有此行数据(根据主键或者唯一索引判断)则先删除此行数据,然后插入新的数据, 否则直接插入新数据
为了解决单点故障问题:Flicker 方案启用了两台数据库服务器来生成 ID,通过区分 auto_increment 的起始值和步长来生成奇偶数的 ID。(也可以根据情况部署多台服务器)
优点
充分利用了数据库自增 ID 机制,生成的 ID 有序递增。
缺点
依赖于数据库,可用性低
水平扩展困难:定义好了起始值、步长和机器台数之后,如果要添加机器就比较麻烦了。
适用场景:数据量不多,并发量不大。
Redis
因为 Redis 中的所有命令都是单线程的,可以利用 Incrby命令来模拟 ID 的递增。并且可以通过使用集群来提升吞吐量。我们可以为不同的 Redis 节点设置不同的初始值并统一步长,这样就能利用 Redis 生成唯一且趋势递增的 ID 了。例如有 3 个 Redis 节点,分别设置初始值为 1、2、3 ,这时步长就应该定为 3 。这样每个节点不会生成重复的 ID。
Incrby :将 key 中储存的数字加上指定的增量值。这是一个 “INCR AND GET” 的原子操作, 业务方可以定义一个自己的 key 值,通过 INCR 命令来获取对应的 ID。
优点:
不依赖数据库,且性能优于依赖数据库的 Flicker 方案。
缺点:
- 扩展性低,Redis 集群需要设置好初始值与步长。
- Reids 宕机可能会生成重复的Id。
适用场景:Redis 集群高可用,并发量高。
Leaf
上面提到的这些常见的 ID 生成策略,有时并不能完全满足实际生产中的需求,在实际项目中会对其做一些改造和优化。
美团的 Leaf 分布式 ID 生成系统 ,在 Flicker 策略 与 Snowflake 算法的基础上做了两套优化的方案。下文会简单介绍一下 Leaf 方案做的一些优化,并不会深入分析。详细方案大家可以查看这里:《Leaf 分布式 ID 生成系统 》
Leaf-segment 数据库方案
相比于 Flicker 方案每次都需要读取数据库,Leaf-segment 改为了利用 proxy server 批量获取,且做了双 buffer 的优化。设计图如下:
双 buffer:ID 分号段加载,且当号段消费到某个点时就异步的把下一个号段加载到内存中。而不需要等到号段用尽的时候才去更新号段。
Leaf-snowflake 方案
主要是针对时钟回拨问题做了特殊处理。 若发生时钟回拨则拒绝发号,并进行告警。
适用场景:服务规模较大,调用频繁。
总结
关于分布式 ID 的生成策略暂且介绍到这里。其实还有一些优秀的解决方案,比如百度的 uid-generator,微信的 SEQSVR。基本上都是都上面一些方案的优化,这里就不做详细介绍了。在实际使用中,需要根据自身业务场景来选取合适的方案,也并非大而全的方案就是好的方案。
转载
牛在舒,分布式 ID 生成策略
